
什么是爬虫?为什么要使用爬虫?
爬虫(即 网络爬虫 )是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。 (摘取自百度百科)
使用爬虫可以方便地获得某个网页,或者某系列网页一些规则下的内容,由按照规则自动执行地脚本来代替手动查询内容等繁琐工作。
将要使用到的技术或知识:
一、第三方库Beautiful Soup安装
Beautiful Soup: Python 的第三方插件用来提取 xml 和 HTML 中的数据。 官网
1、安装Beautiful Soup
打开 cmd(命令提示符),进入到 Python(Python2.7版本)安装目录中的 scripts 下,输入 dir 查看是否有 pip.exe, 如果用就可以使用 Python 自带的 pip 命令进行安装,输入以下命令进行安装即可:
1 | pip install beautifulsoup4 |
2、测试是否安装成功
编写一个 Python 文件,输入:
1 | import bs4 |
二、分析网页
实战爬取 樱花动漫 Top100动漫的下载链接
(注意:仅供学习思路,如学习请爬取其他网站,尊重他人的服务器,也请自重)
0、首先进入主页
进入主页后,可以发现这是一个动漫粒度的列表页,我们查看列表出的网页源代码。** 列表处 - 右键 - 检查**
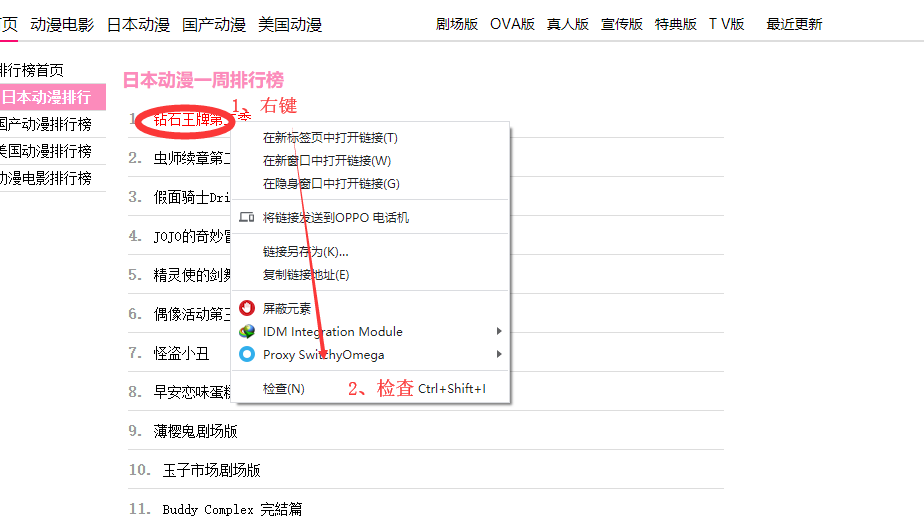
Top100列表页
1、分析Top页面
先分析网站层级关系,可以发现在class=”topli”的div标签下,有无序列表ul>li来存放每个动漫的入口,使用a 标签的href属性指定了当前动漫详细页面的url 如:domain/view/1794.html(如下图所示)。使用下面代码来获取这些li标签( 其中domain为该网站域名 http://www.imomoe.in/ )
divs = soup.findAll(name="div", attrs={"class": "topli"}) topk = divs[0].ul.findAll(name="li") # 至此,我们的topk已经获取到了所有的动漫的详情页链接
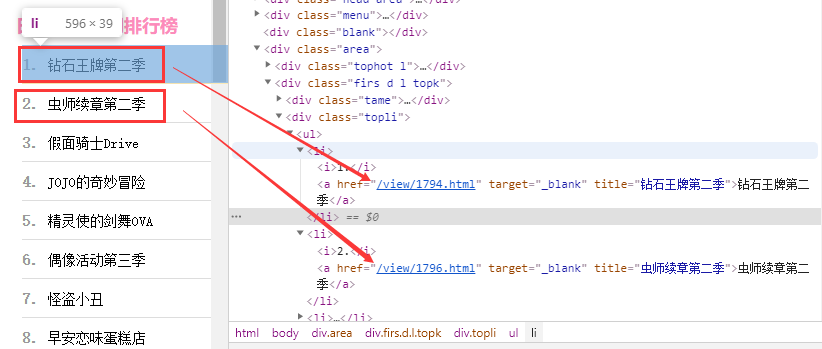
Top页面分析
2、分析详情页
我们随便点进去一个动漫,可以发现动漫详情页,继续查看源代码,可以发现,这一层的结构和上一层的几乎一致。
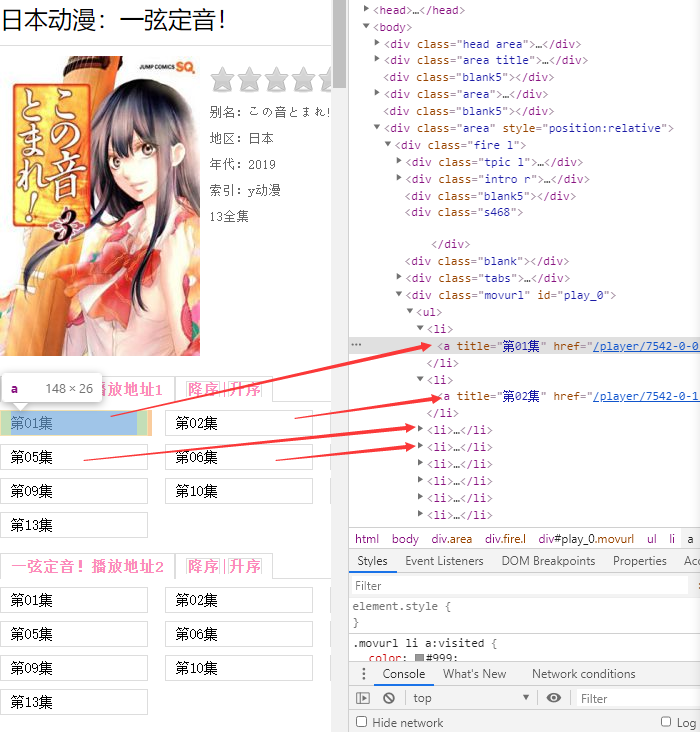
动漫详情页
3、分析视频播放页
这一步的目标,是通过
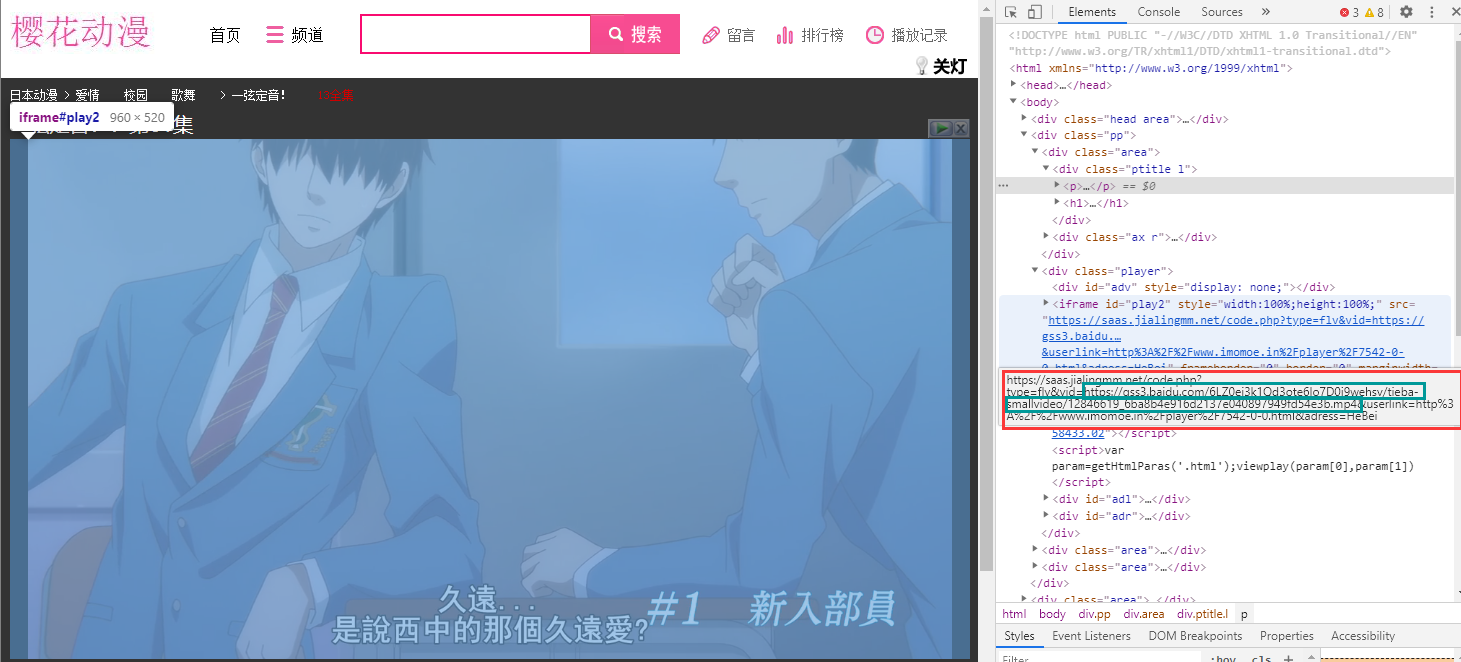
视频播放页
4、尝试爬取
我们通过CMD的curl命令来查看视频播放页的iframe标签(如下图),却发现其中的src为空,并没有像浏览器访问时候所显示的URL,那么,我们如何爬取下载链接呢?
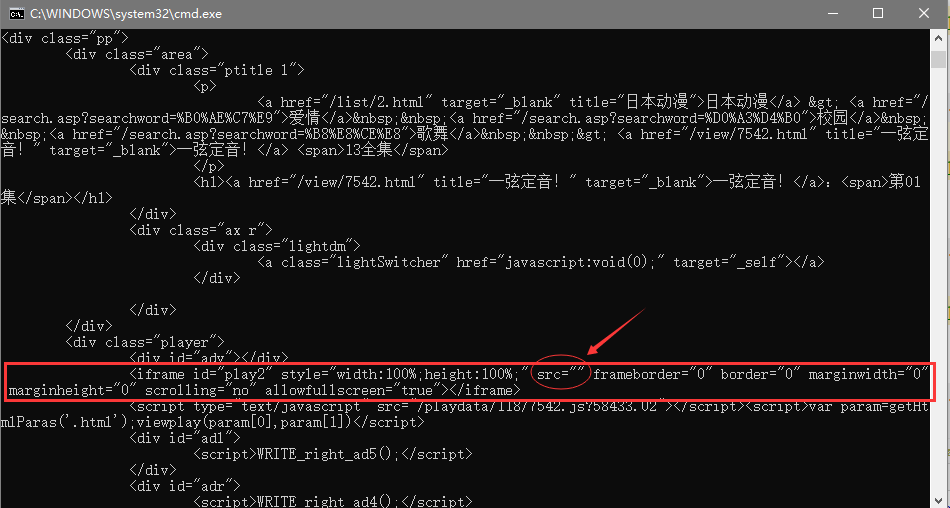
进一步分析,这个iframe标签的src,既然不是访问的时候存在的,则是通过js动态生成的,顺着这个思路,我们寻找一个比较像的js文件,其实就在iframe标签后面(如下图)
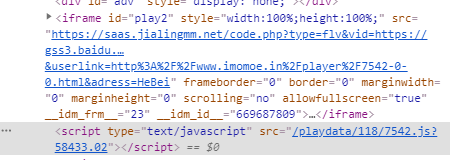
我们通过主机域名+js的src,访问,可以发现这个js文件包含这个动漫的所有下载链接,如下:
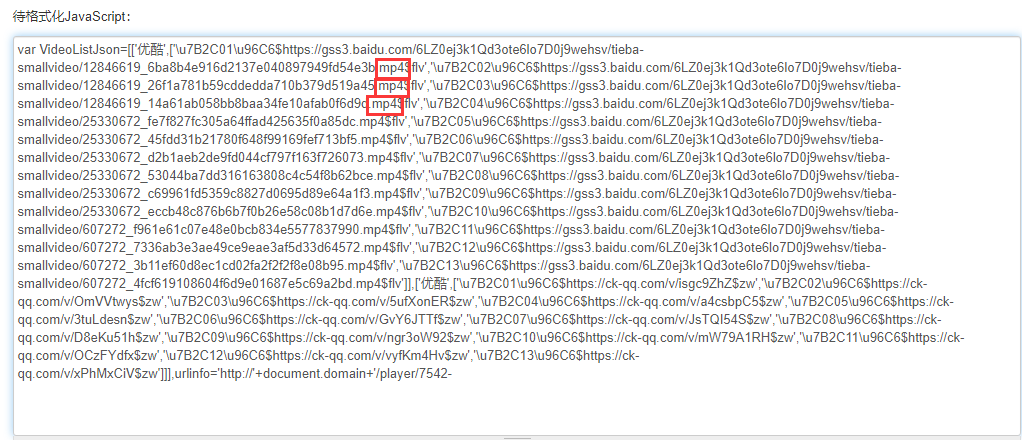
JS文件
1 | var VideoListJson = \[\['优酷', \['\\u7B2C01\\u96C6$https://gss3.baidu.com/6LZ0ej3k1Qd3ote6lo7D0j9wehsv/tieba-smallvideo/12846619\_6ba8b4e916d2137e040897949fd54e3b.mp4$flv', '\\u7B2C02\\u96C6$https://gss3.baidu.com/6LZ0ej3k1Qd3ote6lo7D0j9wehsv/tieba-smallvideo/12846619\_26f1a781b59cddedda710b379d519a45.mp4$flv', '\\u7B2C03\\u96C6$https://gss3.baidu.com/6LZ0ej3k1Qd3ote6lo7D0j9wehsv/tieba-smallvideo/12846619\_14a61ab058bb8baa34fe10afab0f6d9d.mp4$flv', '\\u7B2C04\\u96C6$https://gss3.baidu.com/6LZ0ej3k1Qd3ote6lo7D0j9wehsv/tieba-smallvideo/25330672\_fe7f827fc305a64ffad425635f0a85dc.mp4$flv', '\\u7B2C05\\u96C6$https://gss3.baidu.com/6LZ0ej3k1Qd3ote6lo7D0j9wehsv/tieba-smallvideo/25330672\_45fdd31b21780f648f99169fef713bf5.mp4$flv', '\\u7B2C06\\u96C6$https://gss3.baidu.com/6LZ0ej3k1Qd3ote6lo7D0j9wehsv/tieba-smallvideo/25330672\_d2b1aeb2de9fd044cf797f163f726073.mp4$flv', '\\u7B2C07\\u96C6$https://gss3.baidu.com/6LZ0ej3k1Qd3ote6lo7D0j9wehsv/tieba-smallvideo/25330672\_53044ba7dd316163808c4c54f8b62bce.mp4$flv', '\\u7B2C08\\u96C6$https://gss3.baidu.com/6LZ0ej3k1Qd3ote6lo7D0j9wehsv/tieba-smallvideo/25330672\_c69961fd5359c8827d0695d89e64a1f3.mp4$flv', '\\u7B2C09\\u96C6$https://gss3.baidu.com/6LZ0ej3k1Qd3ote6lo7D0j9wehsv/tieba-smallvideo/25330672\_eccb48c876b6b7f0b26e58c08b1d7d6e.mp4$flv', '\\u7B2C10\\u96C6$https://gss3.baidu.com/6LZ0ej3k1Qd3ote6lo7D0j9wehsv/tieba-smallvideo/607272\_f961e61c07e48e0bcb834e5577837990.mp4$flv', '\\u7B2C11\\u96C6$https://gss3.baidu.com/6LZ0ej3k1Qd3ote6lo7D0j9wehsv/tieba-smallvideo/607272\_7336ab3e3ae49ce9eae3af5d33d64572.mp4$flv', '\\u7B2C12\\u96C6$https://gss3.baidu.com/6LZ0ej3k1Qd3ote6lo7D0j9wehsv/tieba-smallvideo/607272\_3b11ef60d8ec1cd02fa2f2f2f8e08b95.mp4$flv', '\\u7B2C13\\u96C6$https://gss3.baidu.com/6LZ0ej3k1Qd3ote6lo7D0j9wehsv/tieba-smallvideo/607272\_4fcf619108604f6d9e01687e5c69a2bd.mp4$flv'\]\], \['优酷', \['\\u7B2C01\\u96C6$https://ck-qq.com/v/isgc9ZhZ$zw', '\\u7B2C02\\u96C6$https://ck-qq.com/v/OmVVtwys$zw', '\\u7B2C03\\u96C6$https://ck-qq.com/v/5ufXonER$zw', '\\u7B2C04\\u96C6$https://ck-qq.com/v/a4csbpC5$zw', '\\u7B2C05\\u96C6$https://ck-qq.com/v/3tuLdesn$zw', '\\u7B2C06\\u96C6$https://ck-qq.com/v/GvY6JTTf$zw', '\\u7B2C07\\u96C6$https://ck-qq.com/v/JsTQI54S$zw', '\\u7B2C08\\u96C6$https://ck-qq.com/v/D8eKu51h$zw', '\\u7B2C09\\u96C6$https://ck-qq.com/v/ngr3oW92$zw', '\\u7B2C10\\u96C6$https://ck-qq.com/v/mW79A1RH$zw', '\\u7B2C11\\u96C6$https://ck-qq.com/v/OCzFYdfx$zw', '\\u7B2C12\\u96C6$https://ck-qq.com/v/vyfKm4Hv$zw', '\\u7B2C13\\u96C6$https://ck-qq.com/v/xPhMxCiV$zw'\]\]\], |
对于上述JS中包含下载链接,我们可以通过正则去分割出下载链接
1 | video_urls = list(filter(lambda s: s[:4] == 'http', js_text.split(r'$'))) |
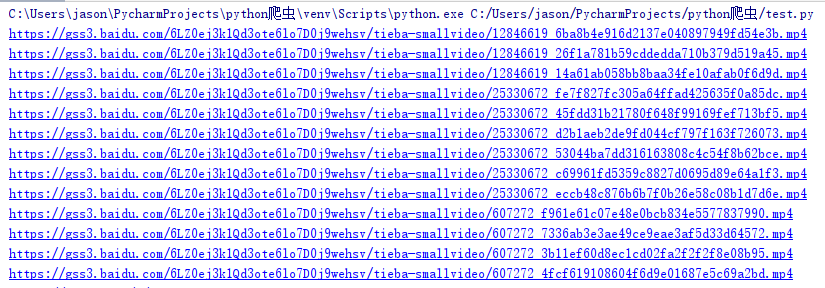
运行结果
最后我们再将链接存到数据库即可。
数据库数据
三、附件
源代码Py文件: 蓝奏云下载
Author: Leisurelybear
Link: https://blog.lebear.top/2020/07/01/194/
Copyright: Copyright © 2019-2022 LeisurelyBear All rights reserved.